[PYTHON] 연관규칙을 활용한 titanic 생존자 예측
from apyori import apriori
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as pltapriori를 활용한 연관규칙을 위해 apyori를, titanic dataset을 활용하기 위해 seborn을 불러온다.
dataset = [['사과','치즈','생수'],
['생수', '호두','고등어'],
['수박', '사과', '치즈'],
['생수', '호두', '치즈','옥수수','사과']]해당 데이터를 연관규칙 분석하는 실습을 해보자.
association_rules = apriori(dataset, min_support = 0.5, min_confidence = 0.8)
association_rules = list(association_rules)
for association_rule in association_rules:
print(association_rule)
print('---------------')해당 코드대로 apriori 연관 규칙을 사용하고 결과를 출력하면

이렇게 된다. 여기서 각 association_rules에는 RelationRecord 객체가 있다. RelationRecord 객체에는 items, support, ordered_statistics가 저장되어 있다. items는 해당 규칙에 포함된 항목들, support는 지지도를 뜻한다. 마지막 데이터인 ordered_statistics에는 해당 규칙에 대한 confidence와 lift가 저장되어 있다.
rules = []
for results in association_results:
supp = results.support
for orders in results.ordered_statistics:
conf = orders.confidence
lift = orders.lift
hypo = orders.items_base
conc = orders.items_add
rules.append([hypo, conc, supp, conf, lift])
for rule in rules:
print(rule[0], '->', rule[1])
print('supprot = ' + str(rule[2]))
print('confidence = ' +str(rule[3]))
print('lift = ' + str(rule[4]))
print()조금 더 직관적으로 확인하기 위해 각 객체들을 활용해 쉽게 볼 수 있도록 출력한다.

이를 활용해 타이타닉 데이터를 불러와 연관규칙을 적용하고 그 내용을 scatter를 활용해 시각화해 보자.
연관규칙을 적용한 타이타닉 생존자 예측
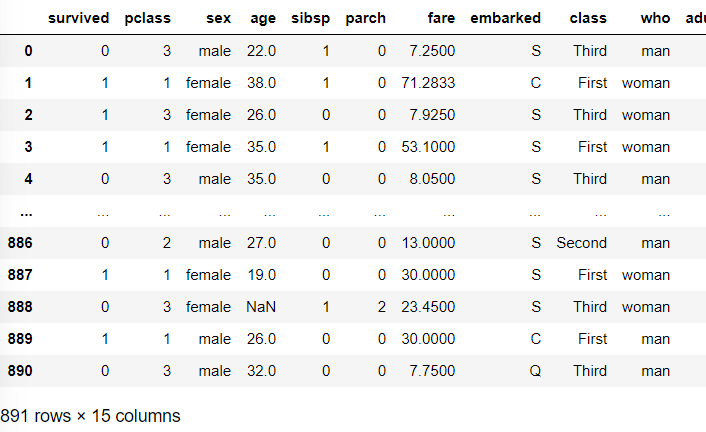
df = sns.load_dataset('titanic')
dfseborn 라이브러리를 활용해 타이타닉 데이터셋을 불러온다.
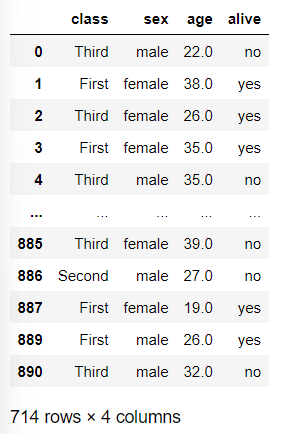
df = df[['class', 'sex', 'age', 'alive']]
df=df.dropna(axis=0)
df사용할 컬럼들만 가져오고 결측치 또한 제거해 준다.
child_idx = df.age < 20
adult_idx = (df.age >= 20) & (df.age < 60)
old_idx = df.age >= 60
df = df.astype({'age':'str'})
df.loc[child_idx, 'age'] = 'child'
df.loc[adult_idx, 'age'] = 'adult'
df.loc[old_idx, 'age'] = 'old'
df분석을 위해 alive데이터를 범주형 데이터로 만들어 준다.

records = []
for i in range(len(df)):
records.append([str(df.values[i,j]) for j in range(len(df.columns))])
records장바구니 분석을 위해선 처음에 했던 예제처럼 리스트 형태로 정리가 되어 있어야 하기에 데이터프레임의 데이터들을 리스트 형태로 만들어준다.

association_rules = apriori(records, min_support = 0.005, min_confidence = 0.8)
association_results = list(association_rules)
association_results최소 신뢰도 0.8, 최소 지지도 0.005로 적용한 연관규칙들을 생성한다.

for results in association_results:
supp = results.support
for orders in results.ordered_statistics:
if(orders.items_add in [{'yes'},{'no'}]):
conf = orders.confidence
lift = orders.lift
hypo = orders.items_base
conc = orders.items_add
rules.append([hypo, conc, supp, conf, lift])
for rule in rules:
print(rule[0], '->', rule[1])
print('supprot = ' + str(rule[2]))
print('confidence = ' +str(rule[3]))
print('lift = ' + str(rule[4]))
print()다시 보기좋게 출력해서 확인해 보자.

labels = ['hypothesis', 'conclusion', 'support', 'confidence', 'lift']
rules_df = pd.DataFrame.from_records(rules, columns = labels)
rules_df_sort = rules_df.sort_values(['lift'], ascending = False)
rules_df_sort = rules_df_sort.reset_index(drop=True)
print(rules_df_sort)만들어 낸 규칙들을 분석 및 시각화의 편의를 위해 다시 데이터프레임 형태로 만들어 준다.

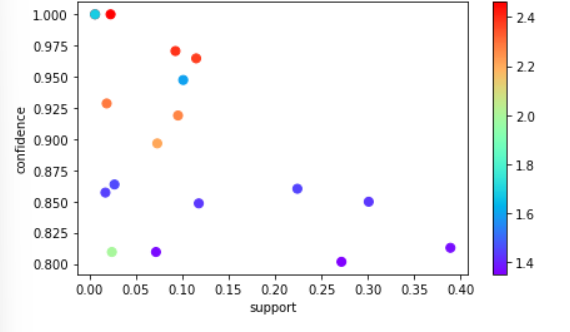
fig, ax = plt.subplots(figsize=(7,4))
scatter = ax.scatter(rules_df_sort['support'], rules_df_sort['confidence'],
s=50, c=rules_df_sort['lift'], cmap='rainbow')
ax.set_xlabel('support')
ax.set_ylabel('confidence')
plt.colorbar(scatter)
plt.show()pyplot을 활용해 지지도를 x축, 신뢰도를 y축, lift를 색으로 표현하는 scatter를 만든다.